
"Coincidentally"
This is part 2 of this topic about geodatabases. Below is a review of where we're at.
The plan:
This series of blogs is going to focus on feature coincidence. To get there will take a number of weeks of blogs to fully post this series. Here's my plan:
Part 1 -- introduce the feature dataset and how to add your shapefiles
Part 2 -- introduce topology and two very useful rules: Must Not Overlap and Must Not Have Gaps
Part 3 -- introduce working with coincidence and Area Boundary Must Be Covered By Boundary Of
Part 4 -- editing Area Boundary Must Be Covered By Boundary Of errors
This information is taken in part from my ArcGIS Desktop: Geodatabase Power User class. For more in-depth detail, you can sign up for my class. More information at Web Classes.
Required software:
Standard or Advanced version of ArcGIS Desktop (it used to be called ArcEditor and ArcInfo) version 10.1. (Much of this can be done with older versions of the software. I cannot keep track of what all works and doesn't work with the older versions.) Since we will be building geodatabases in this series, Basic ArcGIS (ArcView) users don't have all the capabilities.Topology:
In simple terms, topology is a set of spatial rules ensuring geometric relationships or how features exist in relationship to their neighbors. There are 32 rules you can work with. Here is one common rule.


Why use topology? The easiest reason to use topology
is to check and improve your data. Spatial integrity is important to most
users.
When you model geographic features,
you may find that you want to model some features that have spatial
relationships with other features around them. Countries might be modeled such
that adjacent countries meet without gaps along a common border line but never
overlap. States or provinces could be modeled such that they fall exclusively
within one country. Streets may be modeled such that two streets always meet at
an intersection and never share a segment. Bus stops may be modeled such that
they must always occur on a street or certain type of street. These
relationships are maintained in the geodatabase through an association called a
topology.
Topologies enable richer analytical
functions in your GIS. For instance, geometric networks are a special kind of
topology and allow routing and upstream/downstream modeling.
Topologies also allow you to perform sophisticated editing. For instance, you can edit a county boundary at the same time as a city boundary or a road if they are in fact, coincident (which is the objective of this blog).
Why are you not using topology? (Well, in fact, you might. But, if you aren't...) Many people wait to build topology because they’ve seen or heard about involved designs taking weeks or
months to build, test, and implement. They just don't have the time for an involved design.
You don’t have to wait! You can
apply and capitalize on some of the benefits of topology, such as Must Not
Overlap or MustNot Have Gaps. Very simple rules that help immediately and
powerfully!
Certainly, your organization may
want to construct a complex schema, but there is no reason not to start with a
few baby steps and build up from there.
Creating Topology:
A topology is a set of properties. Right-click on a feature dataset (which you learned about in the last part) and choose New > Topology.
Name:
Each topology must have a name. Be sure to name it something that makes sense for your application.
Cluster tolerance:
Cluster tolerance is the minimum
distance between vertices of features. Vertices that fall within the cluster
tolerance are defined as coincident and are snapped together. This may affect
endpoints, vertices along a line segment, or lines of adjoining features or
feature classes.

Image extracted from the ESRI help documentation
The cluster tolerance is very
important to establishing topology. It basically suggests that two points
describing the same or similar features cannot exist on top of each other. For
instance, a line would not have two exact points describing the shape of the
line. Cluster also ‘snaps’ features together such as the figure above. In this
example, the software connects these two features together and eliminates one
vertex. Hopefully, this would eliminate some ‘Must Not Have Dangle’ errors.
Rank
Ranking your feature classes is
very important since you may not want all your data to move during the
verification of rules. A rank of 1 is the highest rank, meaning it is less
likely to move.
If you have two feature classes with one ranked 1 and the other 2, then the
features ranked 2 will move or snap (the to maximum of the cluster) to the
associated features that were ranked 1. This implies an intrinsic level of accuracy or reliability for the rank 1 data.
Bear in mind, just because you have a rank of 1 on a feature class does not mean that that data won't move. The cluster tolerance can and will move your coordinate data.

Rules
There are 32 possible rules you may use (but not all apply to all feature classes). These are organized by the types of features they work with: points, lines, and polygons. I use the chart supplied by ESRI as my first reference for rules. You can find this (if you have a local install) at
c:/Program
Files/ArcGIS/Desktop10.1/Documentation/topology_rules_poster.pdf
The Must be Larger Than Cluster Tolerance rule: This rule is applied within each line or polygon feature class used in a topology. Vertices that fall within the cluster tolerance are defined as coincident and snapped together. Any polygon or line feature that would collapse when validating the topology is an error.
Validating Topology:
After setting rules for your
topology, you will need to validate the rules. During this process two major
activities take place: cracking and clustering.
Cracking happens when the vertex of
one feature in the topology is within the cluster tolerance of an edge of any other feature in the
topology. The topology engine then creates a new vertex on the edge (cracking)
to allow the features to be geometrically integrated in the clustering process.
Clustering happens next. All
vertices of any feature class that participate in a topology can potentially
be moved if they fall within the cluster tolerance of another vertex. Vertices of higher-ranking
features will not move towards lower-ranking features, but vertices of equal-ranked
features will be geometrically averaged. For instance, end points have a higher
rank than edges, therefore the edge will crack and move to the endpoint.

Image extracted from the ESRI help documentation
The combination of cluster
tolerance and ranking controls your result during validation. Results may be
different than shown above.
You may wish to run multiple tests
changing ranking and clustering so you fully understand what will happen with
your data before you implement the rules and parameters on your full database. If you
choose to do this, make a copy of your data before you start! Validation can
not be reversed – at least in ArcCatalog!
I once had to create a dataset of all the roads for 5 counties in Washington. They needed to be "topologically correct" in that all roads must connect correctly, there was to be no overlaps, and a few other basic needs so that transportation modelling could occur. The roads for each county were in various states of "cleanliness". Suffice it to say that they were NOT clean. I had intersections that did not intersect, county boundaries that "shifted" the data (as they were collected by different people and methods), I had duplicate lines, I had overshoots, and I had many other small errors. All these roads were segmented in that they started and stopped at each intersection. I had a couple hundred thousand road segments. Validation took about 150 hours! Now this was a while back when I didn't have as powerful a machine. The point here is that this process may take a huge amount of processing time.
There are ways to help organize and reduce your work when validating a topology, but that's beyond the scope of this blog. Read the documentation, test your ideas on SMALL sets of data, think about your goals and critically evaluate your results. I can tell you by experience, I've been very surprised by some of my results.
Errors:
Validation finds errors. An error is a violation of a rule.
An exception is an error that you
have determined should be allowed, such as Roads typically have lots of dangles
so you may wish to ‘Except’ them. The exception might be a cul-de-sac or a road
that actually dead-ends.
Dirty areas are regions surrounding
features that have been altered by editing after the initial topology
validation process and require an additional topology validation. This
additional verification may well create new errors which you may need to take
action upon.
All of these help you keep track of and identify ‘issues’
in your data. Just remember, an issue may not be a problem or even a data
error.
Visualizing Errors:
Here are the properties for an example topology:
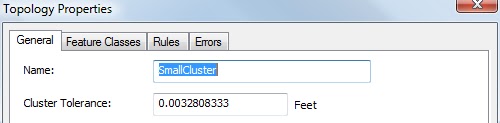
Note the cluster tolerance happens to be very small. This is the minimum distance that can be used and it's automatically calculated by the software. You can increase the cluster tolerance, but why in this case? Keep the data as precise as originally collected.

When applying rules to a single feature class, ranking is irrelevant.

I've applied two simple rules that I feel are basic for most parcel feature classes. Parcels need to be full coverage and non-overlapping.
Okay, so now let's look at some results.

Above, shows an error highlighted in pink that goes around the exterior of all the parcels. This error always occurs with the Must Not Have Gaps rule. If you look closely in the middle of the densest parcels (upper middle), you will see a pink spot.

Zoomed into that spot, you can see very easily that a parcel is missing. This is an error related to the Must Not Have Gaps rule. It's very easy to locate gaps in your data, particularly when you have 1000's of polygons to look at.

Zooming into the pink blotch towards the lower right of the parcels, you will see a lot of parcels not only outlined but filled in as pink. These happen to be exact duplicates of parcels. What likely happened here is that this was an area of development that got updated and an insert was performed twice. You would never be able to visualize this issue when looking at the parcels, whether or not you filled them in with a solid color. Additionally, there seems to be a line problem, yet we are working with polygons. In the next part of this blog, we'll take a look at this error, and others to see what is going on.
Errors can be visualized a number of ways. You also get a report of all the errors to help you sort out what is happening. There's not enough room in this blog to go into these other tools you have available. Again, this topic is a subset of the my ArcGIS Desktop: Geodatabase Power User class. For more in-depth detail, you can sign up for my class which is coming up in a couple of weeks. More information at Web Classes.
Notes About Topology:
- A topology must be in a feature dataset (FDS)
- All feature classes involved in a topology must be within the FDS
- A FDS may have many topologies
- A feature class can be involved in only one topology
- A feature class may have many rules applied to it within that topology
- All points, lines and polygons have the potential to move.
- Just because a feature class can only be involved in one topology doesn’t mean that it can’t be involved in multiple rules.
- When creating or validating a topology, an exclusive lock is required (since this is a schema change and will likely be moving data). An exclusive lock can only be acquired if no other locks—shared or exclusive—are already on the data. If there are already other locks on the feature class or table, ArcCatalog will not be able to establish its exclusive lock, and the schema will not be editable. Once an exclusive lock has been acquired, no shared locks can be applied, so the data will not be accessible in ArcMap or ArcCatalog. A common ‘shared lock’ that will prohibit the construction of a topology is an ArcMap document open and ‘reading’ the data
I need your help:
This sounds really silly, but I love the beginning image and having Dr. Evil and Minnie Me for the first two posts, but now I'm running out of ideas for the opening image! Any ideas for part 3 and 4?
As always, I appreciate your comments, suggestions, and even spelling correcetions!
Happy Geodatabasing!
.jpg)
This comment has been removed by a blog administrator.
ReplyDelete